

by Shiva Molabanti
Solving Data Lake Challenges with Databricks Delta Lake
What is Data Lake:
Data lake drive is what is available instead of what is required. The typical data lake is a storage repository that can store a large amount of structured, semi-structured, and unstructured data. It is a place to store every type of data in its native format with no fixed limits on account size or file. It offers high data quantity to increase analytical performance and native integration to implement Machine Learning and AI models to make profitable predictions. This enables the 360 degrees view of customers and makes the analysis more robust to offer a competitive advantage to the organization.
Apache Spark Is in Rescue to Gain Knowledge of Data Lakes at Scale:
It's important to acknowledge, though, of course, that just storing data is one thing. It's what you do with it that counts. It's going from data to knowledge to insight in terms of actually bringing those data points together that enables organizations to generate wisdom and gain value from storing that data, which is what this absolutely has to be about fundamentally.
The way that we've seen organizations bring data points together is obviously through querying data. The way that most organizations have traditionally queried data has been with SQL. Hence, we've witnessed SQL coming to NoSQL environments and also SQL on Hadoop. That's where Apache Spark, as a computing engine, comes in to play a crucial role in processing the data at a massive scale. As such, it is an excellent vehicle to scale our analytics.
Spark has many capabilities that make it ideal for all analytics and data science use cases in a data lake, such as close integration with Hadoop and Hive, the ability to cache data into memory across multiple nodes, data transformers, and its Machine Learning libraries.
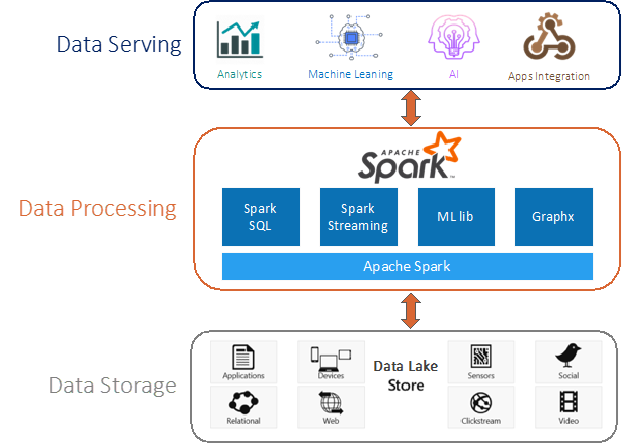
Current Data Lake Challenges:
While data lakes allow us to flexibly store an immense amount of data in a file system, and Apache Spark helps to process the data at scale, there are some challenges that make -the data lake completely flooded.
- Consolidation of streaming data from different systems is difficult
- Apache Spark is not ACID compliant
- Updating data in a data lake is nearly impossible. When updating the data using spark, it does not utilize any locking and is not atomic. And, the data will be deleted before writing out the new data. Reference: https://spark.apache.org/docs/latest/sql-data-sources-load-save-functions.html#save-modes
- Query speeds for data lake are typically slow
- Data lake doesn't enforce Schema which causes unsafe writes
- Missing schema evolution yields in storing orphan data leaving the new or deleted columns from new incoming data
- Hot path for streaming - Need different tech stack for hot & cold layers. Lambda Architecture
- Too many small files in real-time scenarios is a big problem to handle the writes or reads with the following reasons:
- Time taken to list all Files for a given table
- Time taken to Open/Close the many files to perform read/write
- The Small files always have Reduced Compression effectiveness together
- Excessive metadata to keep track of all the smaller files
The Delta Lake is the Answer to Solve All the Data Lake Challenges
What is Delta Lake:
Delta Lake is an open-source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs.
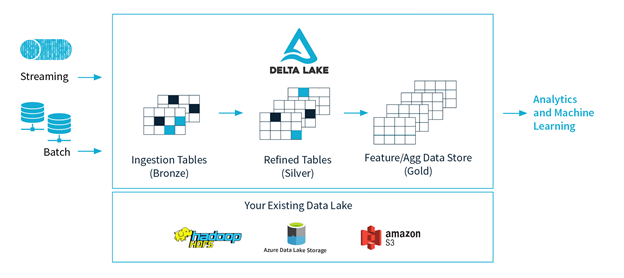
Easy to Adapt Delta in Your Existing Data Lake:
It's very simple to use the Delta storage format in your existing Spark applications.

Delta Lake Brings Reliability to Data Lakes
Delta Lake solves all current challenges in data lake implementations and makes it to run at data warehouse speeds.
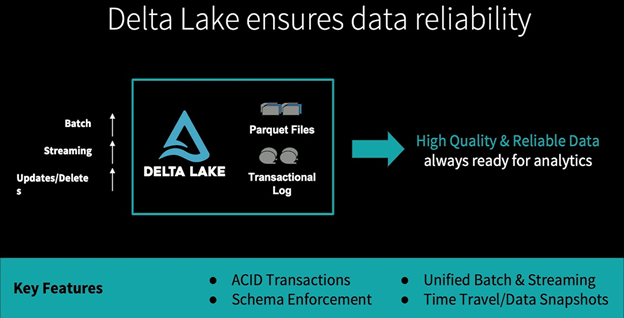
The Delta Lake Key Features:
- Delta Lake brings ACID Transactions to data lakes with Spark
- Delta Lake Enforces the Schema to ensure that the data types are correct and required columns are present, preventing bad data from causing data corruption.
- Metadata Handling: Evaluates the table schema automatically without cumbersome DDL
- Unified Batch & Stream processing with Spark. Delta Lake, along with Structured Streaming, makes it possible to analyze streaming and historical data together at data warehouse speeds
- Upserts are supported on Delta Lake tables so changes are simpler to manage. This allows us to easily comply with GDPR and CCPA & CDC use cases
- Spark reads the data from only committed files details are provided in the commit log files
- The delta tables are AUTO REFRESHED. You don't need to refresh every time when there are some updates/deletes/inserts. The AUTO REFRESH feature is a lifesaver when we are trying to read the most recent data with Realtime inserts/updates to the same table
- Delta Time Travel lets you to query the data from different commit times for audits, rollbacks or to reproduce experiments
- Delta Audit History feature provides transaction log records details about every change made to data providing a full audit trail of the changes
- Currently (as of version 0.1.0) querying data from Apache Hive & Presto is not possible to query Delta Lake tables with Apache Hive nor is the Hive metastore supported. It's in Roadmap to release soon
- Experimental support for Snowflake and Redshift Spectrum - You can now query Delta tables from Snowflake and Redshift Spectrum
- Databricks Enterprise Features: The following are some of the optimizations available with Delta Lake on Databricks Platform
- Compaction(bin-packing)
- Z Order Clustering
- Optimized layouts and indexes for fast interactive queries
- Data Skipping & Many More
More Info:
- Databrick Delta Lake Overview
- Delta Lake is an open-source storage layer
- New Databricks Delta Features Simplify Data Pipelines
- Processing Petabytes of Data in Seconds with Databricks Delta
- Databricks Delta Lake Enterprise Features
Shiva Molabanti is Senior Practice Director at KPI Partners, and Master and Thought Leader in the BI, Big Data and Applications community. He is a renowned writer and architect in the data and analysis community and received numerous applause from customers for enabling/ helping their business growth through value added technology and innovation. He is an enthusiast who likes to blog about acquisitions in the data analytics space. Visit Shiva at his personal blog or check out Shiva's blog at KPIPartners.com.





Comments
Comments not added yet!