by Sristi Raj
With the advent of cloud data warehouse and analytics tools, concepts like data lake, in-place querying, schema on read and data mashup have become a critical and integral part of an organization's analytics capabilities. Consequently, new tools and features like AWS Redshift spectrum, Athena, Presto, Hive etc. are now playing a game changing role for data analysts to explore and mine data and get value out of existing data assets lying unused within the organization. Although, with so many options to choose from, it becomes utterly necessary to understand the subtle differences between each of them and advantages of each, to select the right tool of choice for a particular use case. With this blog, we will explore some capabilities of Redshift spectrum and advantages of using it in some of the use cases, while keeping the comparison and differences between different tool of choice to a separate blog post.
What is AWS Redshift Spectrum?
As per Amazon AWS Redshift spectrum is a capability or a service which can be enabled with AWS Redshift that enables you to run SQL queries directly against all your data, out to exabytes, in Amazon S3 and for which you simply pay for the number of bytes scanned.
With Amazon Redshift Spectrum, you now have a fast, cost-effective engine that minimizes data processed with dynamic partition pruning. You can further improve query performance by reducing the data scanned. You do this by partitioning and compressing data and by using a columnar format for storage.
Pretty clear from the above that Redshift spectrum is a service that can be enabled with AWS Redshift database to query on the data stored in AWS S3 buckets as files. This would sound similar to external tables in Oracle or SQL server database, but with a lot more flexibility and features which I would discuss later in the post.
How AWS Redshift spectrum works?
AWS Redshift is able to query the data stored in files sitting in S3, using external tables (yes, external tables similar to Oracle or SQL Server) created in a Redshift schema which is an external schema. All external tables have to be created inside an external schema created within Redshift database. This is for Redshift to manage the tables within its database cluster.
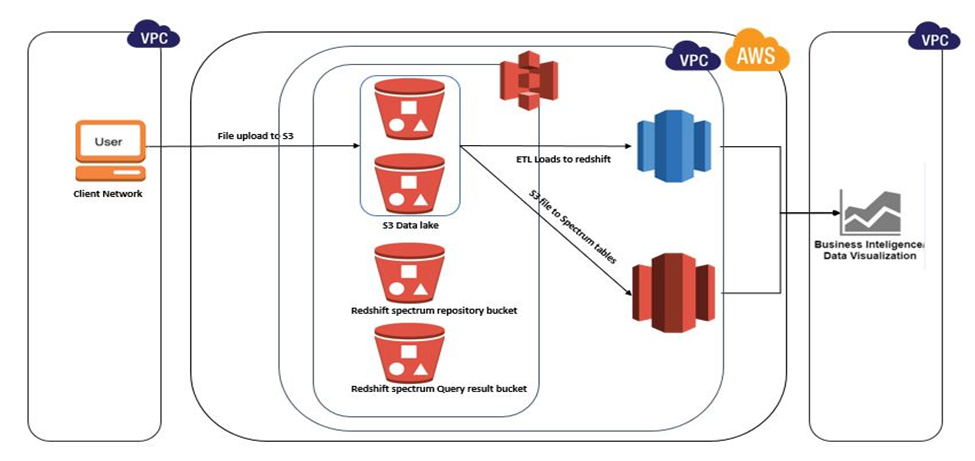
Fig: Redshift Spectrum Working Model
AWS Redshift spectrum gives a huge upper hand for any organization trying to be data driven and get immediate value out of their data.
How to create and access S3 files using Redshift spectrum
Assuming that you already have a Redshift cluster launched in your AWS account, we will see different steps we need to carry out to get started with using Redshift spectrum.
Create an S3 bucket for data files
Create a S3 bucket to store the data files within the bucket. For our example, we are going to create a bucket s3-kpi-monthly-datafile-gl. A bucket in AWS can be considered to be a master folder to store file objects within it. A bucket name is a global name across the AWS platform and hence needs to be unique. If a name is already used by any one else using AWS platform, AWS will not allow you to create the bucket with same name.
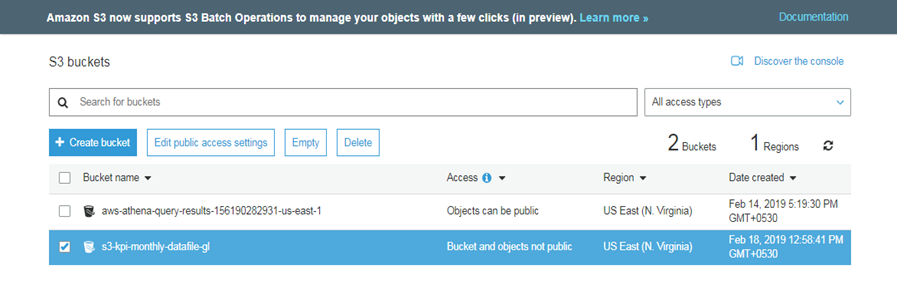
Upload the data file to the S3 bucket
Sample data file with adjustment data uploaded to S3 bucket s3-kpi-monthly-datafile-gl
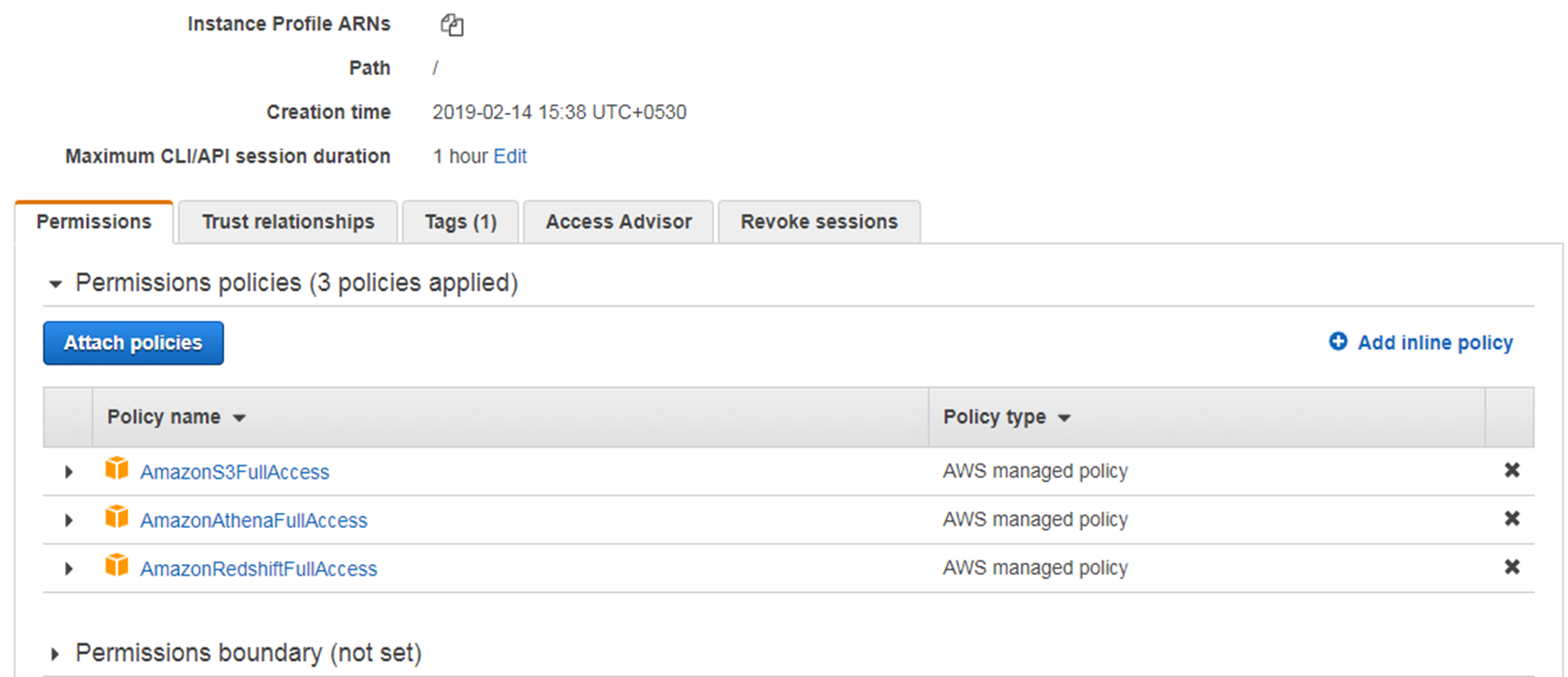
Create an IAM role within AWS account
Create an IAM role having privileges to access S3 buckets, data catalog and Redshift. For demo purpose, we will create role named 'RedshiftAccessForSpectrum' add Full access privilege for S3 and Redshift.
These access would enable Redshift spectrum to access data folder in S3 and Athena data catalog for maintaining the metadata.
Create external schema in Redshift
All the external tables within Redshift has to be created inside an external schema. The external schema 'ext_Redshift_spectrum' created can either use a data catalog or hive meta store to internally manage the metadata pertaining to the external tables like table definitions and datafile locations.
CREATE EXTERNAL SCHEMA ext_Redshift_spectrum FROM DATA CATALOG DATABASE 'athenadatacatalog' Region 'us-east-1' IAM_ROLE 'arn:aws:iam::156x9028xxxx:role/RedshiftAccessForSpectrum';
Here,
athenadatacatalog - The data catalog that would be created if it doesn't exist that would maintain the spectrum metadata related to external tables.
RedshiftAccessForSpectrum - AWS IAM role that grants Redshift access to read data files from S3 and access Athena data catalog.
Create external table in the schema
External table to be created using a csv file uploaded in the S3 bucket 's3-kpi-monthly-datafile-gl'.
External tables can refer to any number of files uploaded inside the bucket or bucket folder provided the file structures remain the same. This would make the table more dynamic and would not need to recreate the table every time a new file is uploaded to the bucket.
CREATE EXTERNAL TABLE ext_Redshift_spectrum.adjustment_details_ext (OP_UNIT_NAME VARCHAR(100),ADJ_NUMBER INT,ADJ_TYPE CHAR(3), ADJ_APPLY VARCHAR(30),ADJ_GL_DATE VARCHAR(30), GL_POSTED VARCHAR(30), TRX_NUMBER INT, TRX_DATE VARCHAR(30), AMOUNT DECIMAL(22,7),FRIGHT_ADJ DECIMAL(22,7),LINE_ADJUSTED DECIMAL(22,7),REC_CHARG_ADJ DECIMAL(22,7),TAX_ADJ DECIMAL(22,7), APPROVED_BY VARCHAR(10),BILL_TO_CUST VARCHAR(100),CURRENCY CHAR(3),CUSTOMER_TRX_ID INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION 's3:// s3-kpi-monthly-datafile-gl/';
The lines below are used to specify the file format to be accessed. The sample file uses csv format.
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
Advantages of using Redshift spectrum
AWS Redshift is cost effective and fast at exabyte scale
AWS Redshift is a highly scalable MPP database, which can support a hugely complex business intelligence and analytics workload. However, with capabilities comes cost which needs to be kept in mind while designing a data warehouse on top of a Redshift database. Whether it is addition of nodes to existing cluster or spinning out a new cluster, it is always a costly affair for any organization. So, for any data that needs to be stored in Redshift needs a careful consideration. AWS Redshift is spawned as a cluster using either a DC or a DS node depending on the query performance and sizing needs (less than or greater than 500 GB recommended). As data in Redshift grows, need for adding new nodes becomes a point to consider. With new nodes the cost of ownership also increases. However, we all know from a data warehouse perspective, that not all data sitting in a data warehouse are actively queried. So, it is reasonable to say that any cold data can be kept in S3 storage (Standard, IA or glacier) and can be referenced whenever the need arises. Redshift spectrum comes to rescue here as it provides a way to reference data sitting in files inside S3 to be directly queried within Redshift with other hot data stored in Redshift tables. Use case of this can be any data not actively needed for day to day operational and analytical reporting but needs to be stored in query able format for compliance purpose or any data that is mostly needed for monthly/ quarterly / yearly reporting.
As an example, consider a use case when a customer has a total data warehouse size of 5 TB with only 2 TB as hot data while the other 3 TB needs to be only queried quarterly.
Scenario 1 - A 3 node ds2.xlarge Redshift cluster with capability to store 6 TB worth of data enough to accommodate 5 TB customer data. With the cluster running 24x7.
Scenario 2 - A one node Redshift cluster with an on-demand pricing ds2.xlarge nodes and located in us-east-1 region would initially give the capability of store 2 TB worth of data in Redshift. While rest of 3 TB data can be kept in S3-IA storage.
Below table depicts the estimated cost of ownership in both the scenarios:
| Cost Components | Scenario 1 | Scenario 2 |
| Redshift Cluster | 3 nodes x 24 hours x 365 days x 0.85 $/hour = $22338 | 1 node x 24 hours x 365 days x 0.85$/hour = $7446 |
| S3 Storage | -NA- | 3TB x $0.0125 per GB x 12 = $460 |
| Redshift Spectrum | -NA- | 3 TB x 5 $/TB x 4 times a year x 50 users = $3000 |
| Total | $22338 | $10906 |
*The table considers only major costs that would be incurred in both the scenarios.
This can further be reduced by storing the 3 TB data in compressed ORC or parquet format and partitioning the data properly to further reduce the cost.
Redshift spectrum vs Athena
Athena is a Serverless querying service provided by AWS which can also be used to query data stored in S3. There is no need to spin up a Redshift cluster for using Athena. However, Athena is good for initial exploratory analysis to be done on any data stored in S3. For any bigger workloads such as those to be used for business intelligence analytics and dealing with huge volume of data to be combined and joined with multiple Redshift tables, it is always recommended to use Redshift spectrum.
Any user not invested in Redshift would still like to use Athena for querying the S3 data with TCO same or even lesser. However, any customer who are already invested in Redshift will always like to use Redshift spectrum and its engine capabilities to query huge volume of S3 data to get decisions out of both S3 and Redshift data.
Add data lake capabilities to the data warehouse
Data warehouse is a great way of analyzing data to understand the performance metrics within and outside an organization. However, with so much and so many types of data being generated now, it becomes overwhelming to process all the data and transform it to a form which can be stored in a data warehouse. To overcome with the limitation came the concept of data lake. Data lakes are meant to store raw data which can be used for data exploration and visualization. Redshift spectrum provides a data warehouse additional capability of using SQL and any SQL compliant tool to query raw data stored in S3. Spectrum can be used to analyze logs and click stream data coming in multiple forms (XML, logs, JSON) and combine it with data stored in Redshift like customer purchase history to get buyer sentiments or even combine log data with user behaviour to improve employee compliance.
UDF's for Redshift spectrum
UDF stands for user defined function, which can be considered to be similar to RDBMS functions. Redshift as well as Redshift spectrum supports UDF's which can be used in SQL queries written to access Redshift spectrum tables for carrying out complex logic calculation. UDF's in Redshift can be written in simple SQL or can use language like python for carrying out complex computation like model calculation in machine learning.
For the purpose of example, we tried creating a UDF using python logger module to log messages to log file in S3, saving valuable dollars if it would have been written in Redshift tables.
CREATE OR REPLACE FUNCTION f_pylogger(errorMessage)
RETURNS INTEGER
VOLATILE AS
$$
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.info($1)
return 0
$$ language plpythonu;
The above UDF can be called by any ETL process using Redshift spectrum tables and log errors and warning messages to log files in S3.
Security
As with Redshift, spectrum also comes with various security features to handle data security requirements for data at rest and data in-transit. Data encryption options are available at various places like AWS SSE (S3 or KMS) for files stored in S3 which spectrum can decrypt transparently, while reading in Redshift. Further security is also enforced by having Redshift cluster launched within a VPC to restrict data flow inside a private cloud. A point to note here is that, Redshift spectrum currently doesn't support AWS S3 client-side encryption. This would mean any data already stored in S3 with client-side encryption has to be stored with AWS SSE in S3.
Read from compressed files
Redshift spectrum has features to read transparently from files uploaded to S3 in compressed format (gzip, snappy, bzip2). This can provide additional savings while uploading data to S3.
Conclusion
Redshift spectrum is a great tool to have in any organization's bucket using AWS or wanting to get maximum value out of their data in least costly way. It is a smart way to add data lake features inside a data warehouse already hosted in Redshift. For any customer not invested in Redshift already, and who are just trying to explore data can always use AWS Athena and then extend to Redshift and Redshift spectrum for their data warehouse, analytics and business intelligence workload.
Check out our recent customer success story to see how we've helped our client:
Cigna
Do you enjoy the solving technology problems and helping people meet their data analytics challenges? Maybe you would be a good fit for our team. See our job openings.
Sristi Raj is a Lead Consultant at KPI Partners. He has worked extensively on reporting tools like OBIEE, OAC, Hyperion FR and Tableau dealing with data warehouses on Oracle, SQL server, AWS Redshift etc. In addition to his reporting experience, he has extensive experience on ERP technologies like EBS, Oracle JD Edwards. He has implemented Real-Time Reporting of various EBS modules across multiple on-premise as well as cloud platforms.
















