by Manju Das
Manual performance optimization in Denodo Most relevant and most used techniques
We are going to discuss how to optimize the Denodo query to make the most of the optimization in the Denodo platform. Below are the most powerful query optimization techniques that we can apply in Denodo platform manually which will increase the performance significantly.
- Branch pruning in unions
- Alternative wrappers
- Memory usage
- When to use Cache
- Streaming data
- Primary keys
- Data movement
Below is the diagram which simplifies how Denodo parses/optimizes a query.
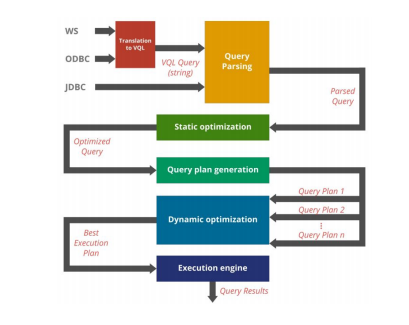
- Denodo first analyze the Denodo VQL query for the syntax. Once Denodo verifies the syntax is correct,
- Denodo static optimizer will come to play which will apply automatic optimization technique included in the Denodo platform such as removing unnecessary joins, Reordering joins, union join push down, full aggregation push down, partial aggregation push down etc.
- Different execution plans will be generated once query is optimized
- Dynamic optimizer will choose the best of the execution plans generated by the query plan generator.
Denodo developers/administrators can also improve the performance of the query using some features provided by Denodo platform.
- Enabling /Disabling the optimizations of the query
- Configuring the data movement explicitly
- Setting primary keys manually whenever possible
- Using cache
- Etc.
In some specific scenarios, it could be advisable to disable the optimization of the query as the process of finding/applying the simplifications and evaluating the best execution plan using cost information might take some milli seconds. For fast queries which return few rows, it may not worth this overhead.
DATA MOVEMENT
Data movement optimization provides a way to execute the queries across distributed data source more efficiently. VDP can transfer the data of a smaller view to a data source of larger view and execute the operation in 2nd DS.
This may offer great performance improvements for the below operations
- Join
- Union
- Minus
- Intersect
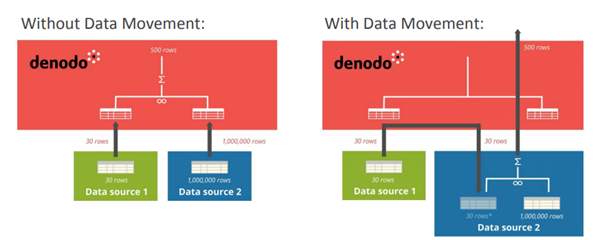
When a query involves a data movement is executed, execution engine does the following.
- Create a temporary table in the target DS
- Retrieves the data from the source and inserts to this temp table (Native bulk load API's are supported for several DS)
- Executes the query in target DS
- Once query finishes, it deletes the temporary tables created to execute the data movement
Only supported data source for cache is available for data movement. The option Allow temporary table for data movement is available under read and write tab of the DS.
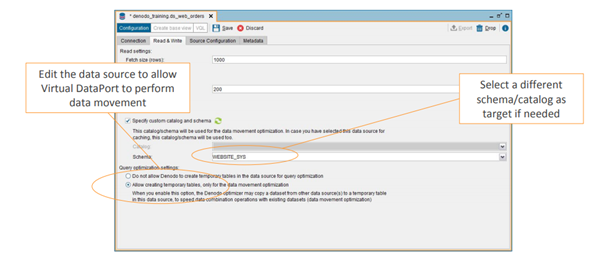
It is also possible to enable the data movement to enable it at the execution time using the DATAMOVEMENTPLAN option in the CONTEXT clause.
Example: Select * from sample_viewname where (DATAMOVEMENTPLAN=samplesourceviewname:OFF target_viewname:JDBC ds1);
PRIMARY KEYS
The primary key of a view is a column or set of columns whose value is unique in the view. At runtime, clients can obtain the primary key definition of a view by invoking the appropriate methods of JDBC or ODBC interfaces of the server. VDP does not enforces the primary key definition.But it plays important role for applying optimizations in Denodo.
BRANCH PRUNING
While dealing with unions, sometimes query needs the result only from one branch. For example, data of current year is stored in one data source and historical data is stored in a different data source, the full union query can be replaced at the execution time by the branch that will be executed by the conditions of the query. This allows delegations of the operations to the DS on top of the union and do not execute an unneeded branch.
Developers have to configure the partitions union by adding Where conditions to the sub views. Each of the selection views defines a clause with conditions that match the data stored in the underlying partition. These conditions actually wont filter any of the rows in the DS when issuing full scan of the view. But when a query specifies a condition that are incompatible with the definition of a certain sub view, Denodo using branch pruning, can be known in advance that subview will return 0 records.
ALTERNATIVE WRAPPERS
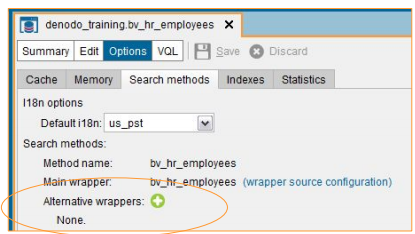
When working with star schema, occasionally fact table is stored in one DB and dimension tables are stored in another DB. For increasing performance, the small dimension tables can be replicated on all the databases of star schema. This allows query optimizer to push down the operations to the DS. This optimization specifically applies only to JDBC Data sources. This functionality is available by going to the base view options -> Search methods
When to use Cache?
Sometimes, real time access to the source is not a good fit and vdp cache can be enabled. Here are some specific situations were enabling cache is advisable.
- Cache for performance: This is the situation were some DS is slower than others which results in overall performance degradation. Example: web service data sources vs JDBC sources
- Optimize frequent queries: There is a pattern of queries with high frequency of users calling for the same data, so these queries can be cached
- Minimize source system impact: Some DS can be accessed massively in the system and cache can be enabled for them to minimize or distribute the load on source system.
- Protect against intermittent system availability: Data sources within the organization can have different availability depending upon the nature of DS.
Memory usage
Query execution in Denodo platform works internally as follows:
For each query, VDP uses one thread for each DS involved in that query and one thread for combining the data obtained from the sources. Each row is returned to the client as soon as it is available, while in streaming mode for asynchronous operations like unions, joins (Not HASH), projections and Selections (not using DISTINCT). For synchronous operations such as GROUP BY, HASH JOIN, ORDER BY, DISTINCT etc., the entire records required to be realized in memory before processing them. For such scenarios following aspects are important when dealing with memory consumption.
- Intermediate results Data is retrieved from the source until they reach a limit in the memory. This limit fixes the size of the queue for the intermediate results. When queue reaches the limit the thread that retrieves the data is paused. When certain percentage is freed, the thread is resumed. This can be set by administrator of the vdb.
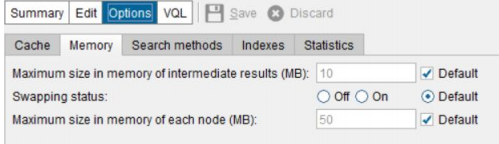
- Swapping Swapping to disk may be necessary to avoid memory overflow errors when executing Synchronous queries, HASH joins, MERGE joins in which right join has lots of rows in which join attributes has same value or when the join uses non-equal operator or queries involving CACHE and large volumes of data.
STREAMING DATA
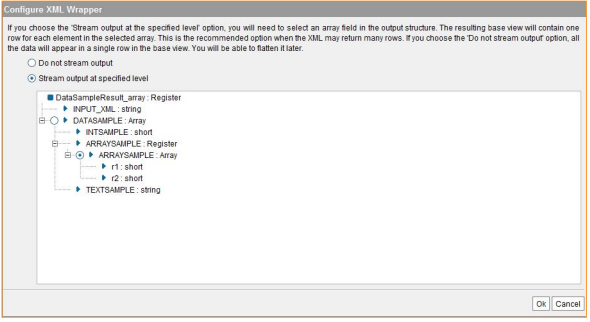
There are 2 options to import a DS with an XML structure which return compound values:
Do not stream output When base view is created, server receives the entire document and then parses it thus having to store the entire document in memory.
Stream output at specified level The server optimizes the processing, so it does not require the entire document to be realized in memory before processing it. The memory consumption is muh lower in this case.
CONCLUSIONS
In general, when dealing with performance, developers should take these same steps:
- Run each query multiple times and write down the total and individual nodes execution times. Saving the full execution trace is a good option and can analyze using trace viewer.
- Data virtualization scenarios, by nature have multiple parts that will affect the performance of the running queries. Few aspects are
- Network performance
- Hard drive behavior
- CPU and memory load in the server including the other processes that are running concurrently with Denodo platform.
Taking time to fully understand the behavior of the queries is critical.
Denodo platform 7.0 reference manuals:
- Removing redunt branches of queries (Partitioned Unions)
- Selecting most optimal data sources
- Streaming Vs no-streaming operators
- Edge cases in streaming operation
Manju is a senior consultant in KPI Partners. Her professional focus is on the world of ETL development, Support, and Implementation. She has extensively worked on Data warehousing applications using ETL tools like Data Stage and Informatica and Data virtualization tool like Denodo and also in SQL, PL/SQL and UNIX scripts.
















