

by Sristi Raj
With the advent of cloud data warehouse and analytics tools, concepts like data lake, in-place querying, schema on read and...

by Sristi Raj
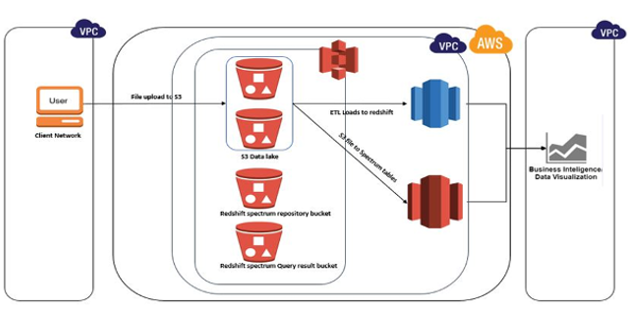
With the advent of cloud data warehouse and analytics tools, concepts like data lake, in-place querying, schema on read and data mashup have become a critical and integral part of an organization’s analytics capabilities. Consequently, new tools and features like AWS Redshift spectrum, Athena, Presto, Hive etc. are now playing a game changing role for data analysts to explore and mine data and get value out of existing data assets lying unused within the organization. Although, with so many options to choose from, it becomes utterly necessary to understand the subtle differences between each of them and advantages of each, to select the right tool of choice for a particular use case. With this blog, we will explore some capabilities of Redshift spectrum and advantages of using it in some of the use cases, while keeping the comparison and differences between different tool of choice to a separate blog post.


by Sristi Raj
With the advent of cloud data warehouse and analytics tools, concepts like data lake, in-place querying, schema on read and data mashup have become a critical and integral part of an organization’s analytics capabilities. Consequently, new tools and features like AWS Redshift spectrum, Athena, Presto, Hive etc. are now playing a game changing role for data analysts to explore and mine data and get value out of existing data assets lying unused within the organization. Although, with so many options to choose from, it becomes utterly necessary to understand the subtle differences between each of them and advantages of each, to select the right tool of choice for a particular use case. With this blog, we will explore some capabilities of Redshift spectrum and advantages of using it in some of the use cases, while keeping the comparison and differences between different tool of choice to a separate blog post.
