

by S. K. Purushotham
This article will help you understand the importance of the MD5 function in Informatica. It will also help you answer questions like:
- What is the Informatica MD5 function all about?
- How does the Informatica MD5 function really work?
- When to use the Informatica MD5 function?
- What are the limitations of the Informatica MD5 function?
What is the MD5 Function in Informatica?
MD5 (Message Digest Function) is a hash function in Informatica which is used to evaluate data integrity. The MD5 function uses Message-Digest Algorithm 5 (MD5) and calculates the checksum of the input value. MD5 is a one-way cryptographic hash function with a 128-bit hash value.
MD5 returns a 32 character string of hexadecimal digits 0-9 & a-f and returns NULL if the input is a null value.
Example:
When you wish to write changed data to a database. Use MD5 to generate checksum values for rows of data that you read from a source.
When you run a session, compare the previously generated checksum values against the new checksum values. Then, write the rows with an updated checksum value to the target. You can conclude that an updated checksum value would indicate that the data has changed.
Change data capture (CDC) can be done in many ways. There are methodologies such as Timestamp, Versioning, Status indicators, Triggers and Transaction logs and Checksum. The advantage of using MD5 function is to reduce overall extract-transform-load (ETL) run-time and the cache memory usage, by caching only the required fields which are of utmost importance.
When To Use MD5 Function in Informatica?
Only update the changed records (any column change) in the target. Instead of passing all existing records to the target for update, ( whether changed or unchanged ) it's always recommended to compare the records.
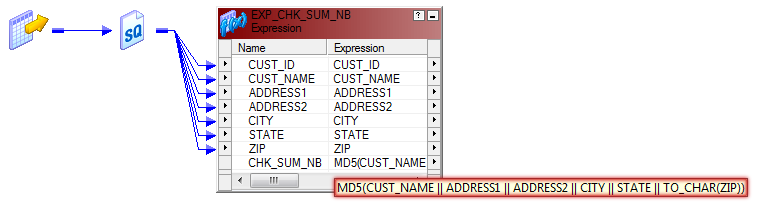
Column-to-column comparison is little painful if your column counts are high. Concatenate all columns and use the MD5 Function (source and target records for the same key) and then compare the output from the MD5 Function. The changed records can be identified and only those records can be updated into the target. This calculation is done really fast and the output of MD5 Function can be used as a unique key to differentiate records
MD5 will help in improving performance when compared to lookups only if the comparison columns are more than 10. MD5 function enhances the performance as compared to lookups only when the comparison columns are more than 10.
Limitations
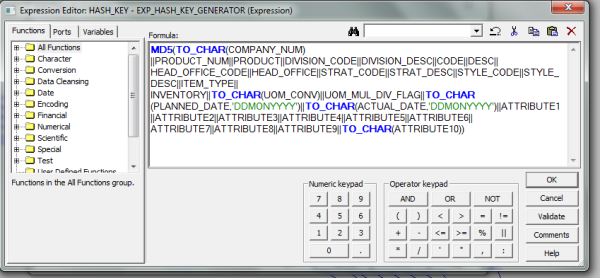
If we have non-string columns (SMALLINT, INT, NUMBER, etc.) we need to convert them into characters using TO_CHAR function because the MD5 Function only validates character strings. If you don't use the TO_CHAR, the output port using MD5 may become invalid. Sometimes it does validate the output port using MD5, but the warning message generated may read validated and non-string data type (e.g. SMALLINT) columns are converted to string. This warning has a great performance impact.
Normal Approach
To identify records for updates and inserts, we use a lookup transformation. The cache built by lookup depends on two factors:
- The number of columns in the comparison condition
- The amount of data in the lookup table.
When there is not a primary key column to identify the changes, there are two options:
- Compare all the columns in the lookup or...
- Compare the data using the concept of power exchange change data capture.
Beware that this can degrade the performance. In this scenario, using the MD5 Function is our best option.
Scenario
Consider a scenario where the incoming Product records consist of PRODUCT_NUM, PRODUCT_DESC, and address fields which have no primary key are associated with them. In such a scenario, it is imperative that a unique identifier be assigned to these records on-the-fly which is immutable. This on-the-fly unique identifier can also be used in future loads as a key to identify whether an incoming customer record is a potential update or an insert.
The MD5 Function generates a unique hexadecimal string 32 which is character-wide for a given input string. In this example, the source table of a customer include customer details such as PRODUCT_NUM, PRODUCT_DESC, and address fields. The MD5 Function in an expression is used to assign a 32 character-wide key to each of these records and load them in target file.
Conclusion
By using the MD5 values, we can identify whether the data is changed or unchanged without the performance being degraded and data is handled in the most efficient way possible. The MD5 value is always recommended for scenarios with many comparison columns and no primary key columns in the lookup table. There is limitation, however; the input to the MD5 values needs to be a string by data type and it returns a 32 bit hexadecimal.

 |
S.K. Purshotham is a Senior Business Intelligence Consultant at KPI Partners. His list of specializations include the customization of Packaged ERP Analytics against source systems such as PeopleSoft, Oracle E-Business Suite, Siebel, and others. Check out Purshotham's blog at KPIPartners.com. |




Comments
Comments not added yet!