

by Prashanth Gajjala
I started working with Oracle Data Integrator (ODI) a year ago while participating in a Oracle Business Intelligence Applications 11.1.1.7 implementation. I have been working with Informatica as the extract-transform-load (ETL) tool of choice for a long time, which included Oracle Business Intelligence Applications and custom warehouse projects.
Moving to ODI from Informatica was a major shift. I was not initially comfortable with the change as I always tried to find functionality in ODI which I used previously in Informatica. This was frustrating. I slowly began to dig into ODI and found out that it’s most advantageous to learn the full capabilities of ODI before trying to accomplish a task rather than trying match Informatica functionality to ODI functionality.
ODI is a great developer oriented tool. This article is an effort to list just some of my findings and comparisons between Informatica and ODI below from a developer's perspective. These are just some my findings from my short time working with ODI...

Extract-Transform-Load (ETL) vs Extract-Load-Transform (ELT)
What does ETL or ELT do? Both ETL and ELT extract the data from one or many source systems (majorly transactional systems), then load it to a target system (majorly data warehouse systems). There will be data transformations performed on the source data to fit the target requirements. These transformations are done between the extract and load process or after the load process based on the environment.
In order to keep the source and target system highly available, the data is extracted as fast as possible from the source with minimum to no impact on the source and loaded into the target with minimal impact on the target to maintain system availability. As target database systems have been evolving, they have become more efficient in processing data transformations. This has also evolved into the option to have transformations performed after loading the data into the target.

ETL
ETL stands for extract, transform and load. ETL is typically performed by an external tool such as Informatica, DataStage or by PLSQL procedures. When tools like Informatica are used, most of the data transformation is done on the ETL server, which made the ETL server to be well built to support the data transformation process. The advantage of this was less impact on the source and target systems.

ELT
ELT stands for extract, load, and transform. The majority of the data transformation is done after the data is loaded into the target database. This will reduce the load on the ETL server and in turn the cost of the server. Since most of the transformation is done on the database, it is also faster, which in turn increases the performance and decreases the duration of the data movement window. This utilizes the capabilities of the target database to increase the performance.
More Oracle Data Integrator Articles at kpipartners.com >>
Similarities
As both Informatica and ODI are tools used to move data from source-to-target with transformations, there are some similarities. I am listing some of those below.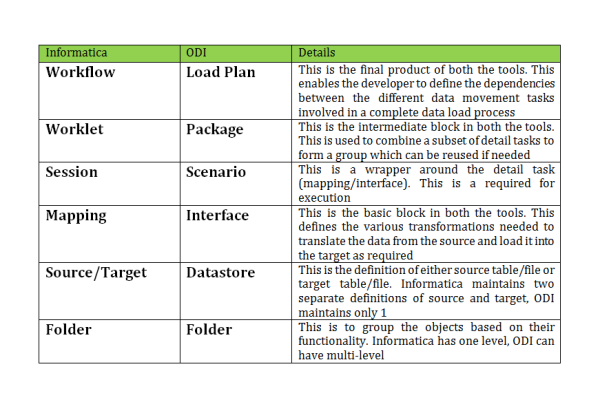
Key Features
Restart Ability from the Point of Failure
Restart from the point of failure is a key feature in any data movement process. This reduces the reprocessing of the same data, which in turn reduces the overall load window. Both Informatica and ODI have restart ability (ODI from 11.1.1.5 onwards). Both offer different levels of restart ability.
In a workflow/load plan, we can configure the restart from the exact point of failure or restart from the beginning of a group based on the failure (earlier versions of ODI did not have load plan and therefore no restart from point of failure was not possible).
Load Dependency
Making sure that the different data sets are loaded in a proper sequence depending on logical dependency is important to the success of any data warehouse implementation. For example, if we have 10 dimensions and 3 facts, the dimensions used in the facts should be completed before the facts are loaded. This can be set by a single level dependency, let all the 10 dimensions complete first and then loaded the 3 facts as shown below in image 1. 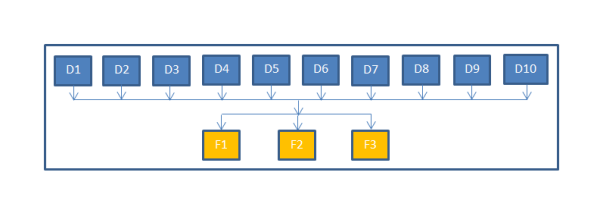
This satisfies the dependencies. If fact1 is only dependent on dimensions 1,2,3 and 4... fact2 is dependent only on dimensions 3,4,5 and 6... and fact3 is dependent only on dimensions 7,8, 9 and 10, the setup in image 1 still satisfies the dependencies, but it has additional dependencies which are not needed. Fact1 is waiting on dimensions 5 to 10 to complete which is not a requirement. This is a bit inefficient and can be refined by adjusting the dependencies as shown in image 2 below.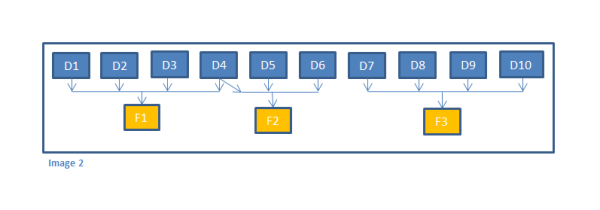
By following the dependencies in the image 2, a better result will be achieved.
Since ODI only recently started to provide the load plan, it is still not fully refined enough to setup the dependencies as shown in the image 2. This can be still achieved in ODI through a package, but that will compromise the restarts ability.
Pre & Post Step Tasks
In any data warehouse load process, there will numerous steps performed before and after a table is loade (e.g. index management steps). Some of the index needs to be dropped before the table is loaded and then recreated after the table is loaded. This is possible in both ODI and Informatica through different approaches as explained below.
In Informatica at a session level, pre and post session tasks can be defined to perform the additional tasks. These can be as simple as drop and create index commands to complex PLSQL commands specific to the database.
In ODI, procedures can be defined by the pre and post session tasks. These tasks can be embedded in the load plan to run before and after the table load step is executed as required.
Truncate Target
Truncating the target table (can be a stage or dimension and fact table) through the automated process is most in any ETL/ELT tool. Both ODI and Informatica have this option available to be configured. ODI has it at the interface level and Informatica has it at the session level.
Unit Testing
Unit testing the independent block of code is required in any data warehouse ETL/ELT implementations. Informatica only allows it at the workflow level as that is the executable (separate workflow has to be built to test each mapping), but ODI allows it at the interface/procedure level as a scenario can be generated at both levels. This saves some time, in the build phase of the implementation.
Reusability of Mapping/Interface in Multiple Session/Scenario
Reusability of a mapping /interface is an important benefit in defining full and incremental loads. This will eliminate the need to maintain two separate mappings/interfaces for full and incremental loads. Informatica provides the ability to define two different sessions on the same mapping with different options like truncate table. This is a built in feature. ODI does not have a built in feature to define the truncate option at the scenario level as this is set at the interface level through the knowledge module. A custom knowledge can be developed to make the truncate option dynamic with the help of some external tables (this has to be developed and tested in house).
Partitioning Option
When the data volumes are high, target tables are partitioned to improve both the ETL/ELT load performance and also the data retrieving performance (reporting performance). Informatica has additional capability to utilize the partitioning in the load process of the table to improve the load time. ODI currently does not have an option but in the process of building a new knowledge module to utilize the partitioning.
 |
Prashanth Gajjal is a Consulting Manager & BI Architect at KPI Partners. He specializes in data tranformation and has over a decade of experience in the area of data warehousing and enterprise decision support systems. Check out Prashanth's blog at KPIPartners.com. |





Comments
Comments not added yet!